
- Building a Real-time Voice RAG Agent:
- Introduction
- Setup RAG
- Setup voice detection
- Create pipeline
- Video demo
- Conclusion
Typing to interact with AI applications can be a bit tedious and boring.
That is why real-time voice interactions will become more and more popular going ahead.
Today, let us show you how we built a real-time Voice RAG Agent, step-by-step.
Here’s an overview of what the app does:
- Listens to real-time audio.
- Transcribes it via AssemblyAI—a leading speech-to-text platform.
- Uses your docs (via LlamaIndex) to craft an answer.
- Speaks that answer back with Cartesia—a platform to generate seamless speech, power voice apps, and fine-tune your own voice models in near real-time.
The code is provided later in the article. Also, if you’d like, we have added a video below if you want to see this in action:
Implementation
Real-time Voice RAG Agent
Now let’s jump into code!
Set up environment and logging
This ensures we can load configurations from .env and keep track of everything in real-time.
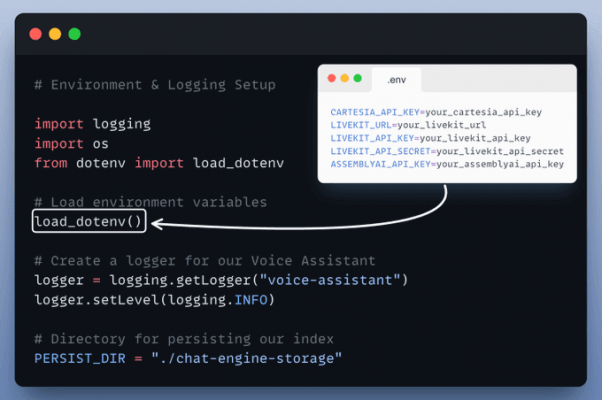
Setup RAG
This is where your documents get indexed for search and retrieval, powered by LlamaIndex.
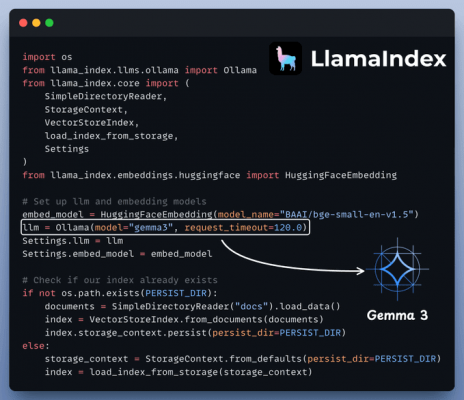
The Agent’s answer would be grounded to this knowledge base.
Setup Voice Activity Detection
We also want Voice Activity Detection (VAD) for a smooth real-time experience—so we’ll “prewarm” the Silero VAD model.
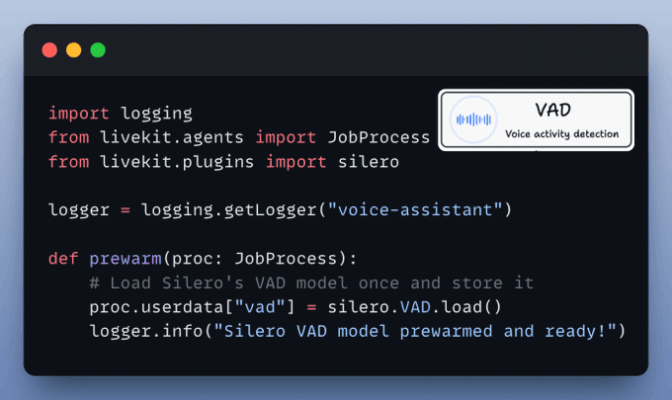
This helps us detect when someone is actually speaking.
The VoicePipelineAgent and Entry Point
This is where we bring it all together. The agent:

- Listens to real-time audio.
- Transcribes it using AssemblyAI.
- Crafts an answer with your documents via LlamaIndex.
- Speaks that answer back using Cartesia.
Run the app
Finally, we tie it all together. We run our agent with specifying the prewarm function and main entry point.

That’s it—your Real-Time Voice RAG Agent is ready to roll!
We added a video at the top if you want to see this in action!