Bạn có biết? Một vài thao tác “Fine-Tuning” thông minh có thể biến một cỗ máy AI khổng lồ thành trợ thủ đắc lực, đưa hiệu suất lên tầm cao mới mà bạn chưa từng tưởng tượng! Hôm nay, mình sẽ bật mí 4 “chiến thuật đỉnh” giúp bạn “cày” AI hiệu quả hơn bao giờ hết: Full-model Fine-Tuning, Fine-Tuning với LoRA, RAG và Agentic RAG. Hãy cùng “lặn” sâu vào từng phương pháp, từ cơ chế hoạt động đến những ưu – nhược điểm, kèm theo những ví dụ thực tế cực chất nhé!
Khái niệm:
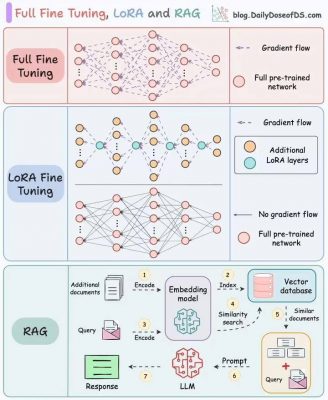
Là quá trình điều chỉnh toàn bộ các trọng số của mô hình đã được huấn luyện sẵn trên một tập dữ liệu mới.
Mục tiêu: Tối ưu hóa mô hình hoàn toàn cho nhiệm vụ cụ thể của bạn.
Ưu điểm:
Tối ưu toàn diện: Mô hình học được tất cả các đặc trưng mới, giúp cải thiện đáng kể hiệu năng.
Ứng dụng đa dạng: Rất hiệu quả khi cần tối ưu hóa cho một nhiệm vụ chuyên biệt mà dữ liệu huấn luyện có chất lượng cao.
Nhược điểm:
Yêu cầu tài nguyên khổng lồ: Đối với các mô hình lớn như LLMs, việc thay đổi toàn bộ trọng số đòi hỏi khả năng tính toán và bộ nhớ vượt trội.
Thời gian huấn luyện dài: Quá trình này không phù hợp với những ứng dụng cần cập nhật nhanh chóng.
Ví dụ minh họa:
Hãy tưởng tượng bạn sở hữu một chiếc siêu xe đắt tiền. Full-model Fine-Tuning chính là việc bạn “tái tạo” lại toàn bộ động cơ, từ cơ cấu đến từng chi tiết nhỏ, đảm bảo chiếc xe hoạt động ở mức tối ưu nhất cho từng điều kiện đường xá cụ thể.
Khái niệm:
LoRA (Low-Rank Adaptation) không “lột xác” toàn bộ mô hình mà chỉ “tách” ra các ma trận trọng số ban đầu thành các ma trận hạng thấp.
Sau đó, ta “đóng băng” phần lớn mô hình và chỉ huấn luyện các ma trận phụ trợ này.
Ưu điểm:
Tiết kiệm tài nguyên: Giảm đáng kể số lượng tham số cần tinh chỉnh, rất phù hợp với mô hình lớn.
Nhanh chóng và hiệu quả: Quá trình huấn luyện trở nên nhẹ nhàng, nhanh hơn nhiều so với full-model fine-tuning.
Nhược điểm:
Giới hạn khả năng tối ưu: Vì chỉ tinh chỉnh một phần, có thể không đạt được mức tối ưu cao như full-model fine-tuning trong một số trường hợp.
Ví dụ minh họa:
Hãy tưởng tượng bạn muốn “nâng cấp” chiếc siêu xe của mình, thay vì thay đổi toàn bộ động cơ, bạn chỉ lắp thêm một bộ turbo siêu hiệu quả giúp tăng tốc đột biến – mà không phải thay đổi cấu trúc tổng thể.
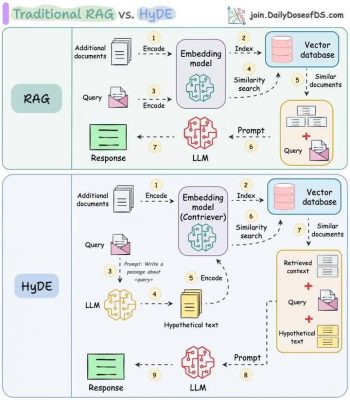
Khái niệm:
RAG là kỹ thuật kết hợp khả năng truy xuất thông tin từ một cơ sở dữ liệu vector với sức mạnh tạo ngôn ngữ của LLM.
Quy trình hoạt động:
Embed và lưu trữ dữ liệu bổ sung vào cơ sở dữ liệu vector.
Embed truy vấn của người dùng để “lấy” ra các tài liệu có nội dung gần nhất.
Đưa các tài liệu này cho mô hình LLM, giúp tạo ra phản hồi chính xác và giàu thông tin.
Ưu điểm:
Tăng khả năng tri thức: Mô hình không chỉ dựa vào dữ liệu huấn luyện ban đầu mà còn “mượn” thông tin từ kho dữ liệu mở rộng.
Trả lời chính xác hơn: Khi câu hỏi của bạn phức tạp, RAG giúp lấy thêm ngữ cảnh, dẫn đến phản hồi sâu sắc và chính xác.
Nhược điểm:
Khó khăn với sự không nhất quán: Nếu cấu trúc câu hỏi và tài liệu truy xuất có quá nhiều sự khác biệt, mô hình có thể gặp khó khăn trong việc tạo ra câu trả lời thống nhất.
Giới hạn về ngữ cảnh: Nếu nguồn dữ liệu không đủ phong phú, RAG có thể không đáp ứng được các yêu cầu thông tin động.
Khái niệm:
Agentic RAG là bước nâng tầm của RAG. Nó không chỉ đơn thuần truy xuất và tạo câu trả lời mà còn điều chỉnh chiến lược của mình theo từng trường hợp cụ thể.
Mô hình này “tự động” đưa ra các quyết định thông minh: nếu ngữ cảnh chưa đủ, nó có thể tự động “mở rộng” tìm kiếm thông tin hay thay đổi chiến lược xử lý.
Ưu điểm:
Động – Thích ứng: Khả năng thay đổi chiến lược theo từng truy vấn làm cho câu trả lời trở nên linh hoạt và chính xác hơn.
Giải quyết vấn đề phức tạp: Khi đối mặt với các câu hỏi “đầu khó”, Agentic RAG có thể tự “nghịch đảo” quy trình để tìm ra thông tin tối ưu.
Tích hợp với HyDE: Một số phiên bản Agentic RAG còn kết hợp với HyDE (Hypothetical Document Embedding) để “dự đoán” ngữ cảnh trả lời, làm tăng độ chính xác vượt trội.
Nhược điểm:
Độ phức tạp cao: Việc tích hợp thêm yếu tố “điều chỉnh chiến lược” đòi hỏi mô hình phải phức tạp hơn, đòi hỏi nguồn lực tính toán lớn hơn trong một số trường hợp.
Rủi ro hệ thống: Nếu chiến lược tự điều chỉnh không được tối ưu, có thể dẫn đến phản hồi thiếu nhất quán hoặc thậm chí “lạc đề”.
Ví dụ minh họa:
Hãy tưởng tượng bạn có một “trợ lý AI” không chỉ trả lời câu hỏi mà còn biết “lắng nghe” và tự điều chỉnh theo tình huống. Nếu bạn hỏi về “tác động của biến đổi khí hậu”, Agentic RAG không chỉ tìm thông tin từ một nguồn mà còn kiểm chứng từ nhiều nguồn, tự động chọn lọc dữ liệu và đưa ra phân tích sâu sắc nhất, như một chuyên gia thực thụ.
TẠI SAO CHỌN 4 PHƯƠNG PHÁP NÀY?
Mỗi kỹ thuật đều có điểm mạnh riêng:
Full-model Fine-Tuning: Cho phép tối ưu hóa toàn diện nhưng đòi hỏi tài nguyên lớn.
LoRA: Giảm thiểu chi phí huấn luyện, phù hợp với mô hình lớn.
RAG: Mở rộng tri thức thông qua truy xuất dữ liệu ngoài.
Agentic RAG: Tự động điều chỉnh chiến lược, mang lại câu trả lời “động” và linh hoạt, xử lý tốt các truy vấn phức tạp.
Việc áp dụng phương pháp nào phụ thuộc vào mục tiêu dự án của bạn, khả năng tài chính và yêu cầu về độ chính xác cũng như tốc độ phản hồi.
Hãy cho mình biết ý kiến của bạn: Bạn nghĩ công nghệ nào sẽ “bùng nổ” và dẫn dắt xu hướng tiếp theo trong lĩnh vực AI? Bạn đã từng trải nghiệm tinh chỉnh mô hình theo cách nào chưa? Đừng ngần ngại chia sẻ suy nghĩ của bạn trong phần bình luận và chia sẻ bài viết này cho cộng đồng những người đam mê AI!